【采用】社交网络分析与金融反欺诈应用(知识图谱?)
社交网络分析(SNA)算法不是新鲜的,并且已在社交性格影响计算,朋友和产品建议,社交圈分析和其他领域的领域广泛使用。近年来,社交网络分析算法的应用一直在扩展,并已开始应用于各种金融反狂欢领域,并且结果非常好。
为了解释基于SNA的反狂欢,本文简要介绍了SNA的基本原理,然后引入了几种典型的SNA方法。最后,这是金融领域中的反欺诈场景应用程序。为了促进理解,本文将直接忽略一些细节。以下是有助于了解反狂暴建模。如果您想了解SNA的更系统的知识,请参考其他材料。
社交网络分析的基本原理
1。基本知识
1。节点和边缘
顾名思义,社交网络是显示人们之间关系的网络。同样,社交网络分析算法,即研究节点(可理解的成年人)和节点(边缘,可以理解成人与人之间的关系)的算法。通过对关系的研究,可以将节点关系分类为聚集在一起。为了促进以下指标的理解,我们定义了节点n = |的数量。 v |,边缘数m = | E |
2。图,有方向,没有方向图
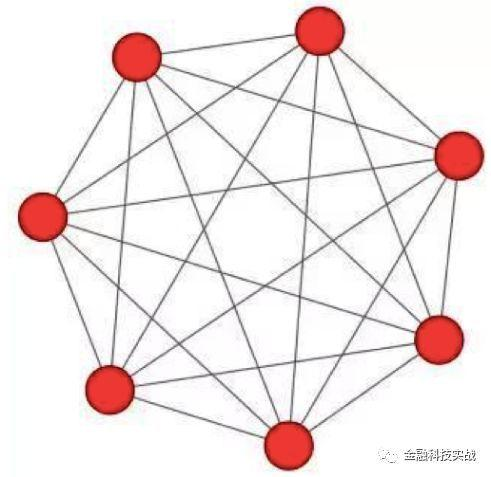
通过与侧面连接节点形成的网络称为图。该图可以分为无关图和方向图,如下图所示:
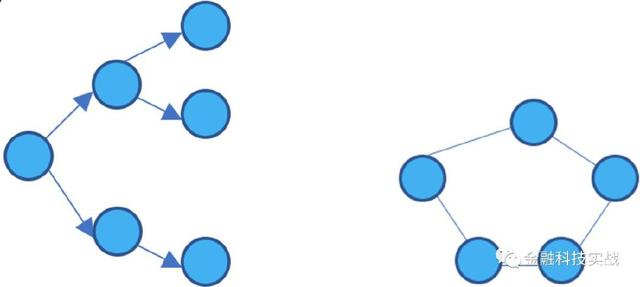
宇宙仅表示节点和节点之间是否存在关系。例如:在P2P行业的反狂暴建模模型中,可以通过申请人的地址簿获得社会关系。例如,如果张圣和李的王有老行王吴,那么张圣和李的违反合同的风险将相对较高。
与方向图相比,有一个方向信息。最简单的例子之一是传销。 MLM具有非常成熟的向上和下线系统。这是发展团队的非常快速有效的方法。互联网公司也广泛使用它来开发用户朋友邀请系统。此外,保险销售公司也有类似的佣金机制。如果使用非法要素的规则,则互联网公司的后果是大规模的错误注册;保险销售公司的后果是与内部和外部欺诈行为串通。
3。社区,非重叠社区,重叠社区
可以将社区理解为UML中的一个群体,即同一社区的中间节点与节点之间的关系密切相关,而社区与社区之间的关系很少。如果任何两个社区的节点集合的交集称为非重叠社区,则称为重叠社区。
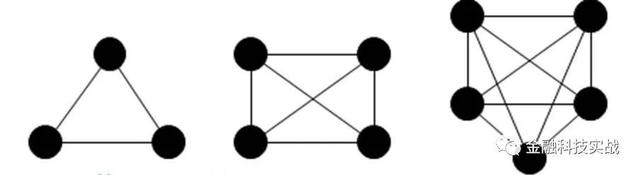
4,派系,完整的子图
该派系是指与其中任何一个连接的节点的集合,也称为完整的子数字。
2。通用分析指标
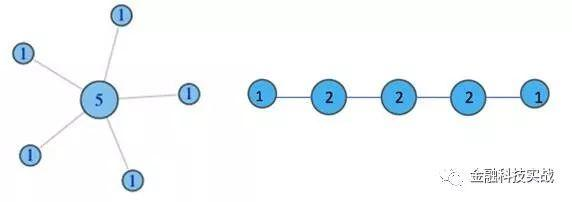
1。学位
简而言之,学位意味着您的节点有多少个边缘,或者您可以拥有多少个朋友。
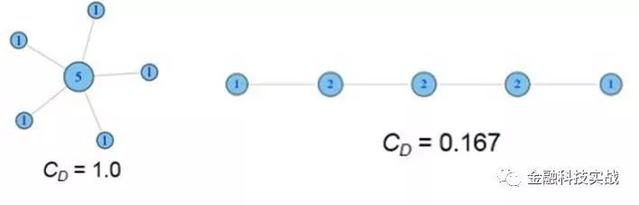
2。权力下放
我们在每个节点上标记了其度的值,如下图所示:
接下来,我们进行标准化治疗,剂量除以最大连接(N-1),然后得到:
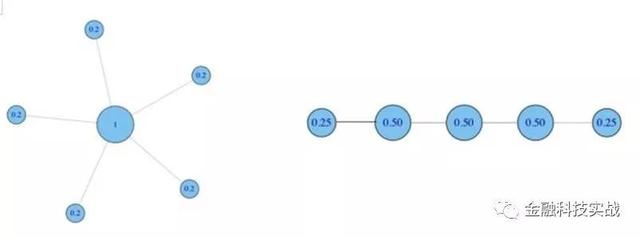
就形象而言爱游戏登录入口网页版平台,中心性越高,与您联系的人越多,或者您的社交特征的影响就越大。当社交网站分析用户行为时,这是一个常用的指标。
3。浓度
浓度代表一个组的紧密度,或者可以理解为密度。浓度可以分为程度浓度,近距和中等浓度以及图浓度,特征矢量浓度等。以下我们主要引入前三种类型。
有很多方法可以在浓度程度上测量浓度,例如天才系数,标准偏差和自由式浓度公式。在下文中,我们以Freeman浓度通用公式为例来计算以下两个数字的程度浓度:
紧密的中心性依赖于从一个节点到所有其他节点的最短路径长度,并定义为总长度的倒计时。通常,我们谈论节点I的紧密中心性,它指的是其标准化形式,即总距离为(N-1)。

从直观地理解,中间性的中间性必须使用节点的数量来达到最小值。以上两个数字被用作计算培养基浓度的一个例子:

通用社交网络分析算法1。Pagerank算法
就古代文本而言,Pagerank算法是“靠近Zhechi,几乎是墨水是黑色的”,也就是说,高品质网页引用的网页也是一个高质量的网页,或者是更多的网页,或者是更多的网页。用户访问可能越高,质量越高。当我们在大学中撰写论文时,我们还会看到类似的数字,例如:期刊的影响因素,参考文献数量。影响因素越高和参考数量,期刊越好。如果它是由此类期刊雇用的,这也意味着您的学术水平已得到广泛认可。在另一个例子中,我相信芝麻信用诚信的每一个apeay用户都提醒:高信用高度信用的朋友可以帮助改善他们的芝麻标记,这是相同的原因。 “黑镜子”第三季的第一集是将信用评分协会夸大为极端,这也是对社交网络的解释。
Pagerarank算法广泛用于搜索引擎结果。为了抵制垃圾邮件,每个搜索引擎使用的排名算法实际上是机密的,并且Pagerank的特定计算方法不相同。
2。社区发现算法
在社区中发现算法的想法是找到复杂网络中连接的紧密节点(社区结构),该节点与聚类的想法完全相同。有很多方法可以找到这些社区结构。本文主要介绍几种简单但常见的算法:GN算法,Louvain算法,LPA算法和SLPA算法。
1)GN(Girvan-Newman)算法
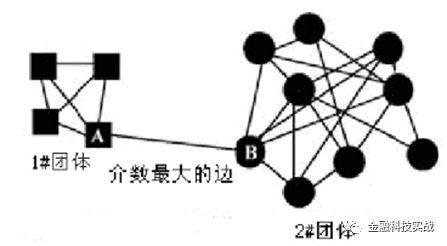
GN算法是最经典的社区发现算法,它属于分裂的层次群集算法(从上到下)。它是由米歇尔·吉尔万(Michelle Girvan)和马克·纽曼(Mark Newman)提出的。 GN算法的基本思想是不断删除网络中网络边缘的最大边缘,然后重新计算网络中其余边缘的边数相对于所有源节点。重复此过程,直到该过程直到重复该过程为止直到过程重复该过程为止。网络中的所有方面都被删除。如何理解?通过介质的定义,我们知道,最小跳跃数量必须实现多少个节点,并且介质的高边缘必须超过社区的边缘。 (两个社区中的节点之间的最短路径必须穿过这些社区的边缘,因此它们的数量将很高)。为了促进理解,您可以参考图,块节点和圆形节点的最短路径,并且必须通过侧面AB。因此,Bian AB的数量最多。该小组被称为两个社区。但是,尽管GN算法的准确性很高,但计算量很大爱游戏app官方网站登录入口,并且时间复杂性很高。
2)Louvain算法
Louvain可以理解GN的逆过程。 GN的想法不断拆卸,类似于顶部下层群集。卢万经常凝结,类似于底部的闭合。为了了解Louvain算法的过程,让我们学习一个社区评估指标 - 模块的程度。模块的程度用于衡量社区的分裂是否相对较好。社区中的节点的一个相对好的结果较高,而社区以外的外部节点的相似性很低。
模块的大小定义为社区内边界总数的比例,即网络中的边缘总数减去所需值。期望值是将网络设置为边界边界总数,边界总数以及网络相同的社区分配。网络中边缘总数的大小。该模块是Q作为Q值。当每次计算Q值时,Q的Q值是网络的理想划分。 Q值的范围在0-1之间。 Q值越大,社区结构的准确性越高除以网络。在实际的网络分析中,Q值的最高点通常出现在0.3-0.7之间。
引入模块的程度后,我们可以开始使用Louvain算法。首先,我们将每个节点视为一个独立社区。如果我们将V1和V2添加到我将增加模块的程度。比较两者的价值,然后选择一个在I社区中增加的价值。反复迭代,直到模块Q的值不再增加。
3)LPA(标签传播算法)
LPA算法的稳定性不是很好,但是优势在于,可伸缩性很强,时间复杂性接近线性,并且可以控制迭代的数量以分裂节点类别。不需要提前给出社区的数量,该社区适用于处理大型复杂网络。 LPA的计算步骤也非常简单:
步骤1:为所有节点指定唯一标签;
步骤2:刷新标签:对于某个节点,检查所有邻居节点和统计信息的标签,并给当前节点提供最多的标签(如果标签不是唯一的话,请随机选择一个);
步骤3:重复步骤2直到收敛。
4)SLPA(扬声器列表标签传播算法)
SLPA是一种改进的LPA,是一种重叠的社区发现算法,涉及重要的阈值参数R。通过适当的R选择,可以将其降低到非高血压类型中。
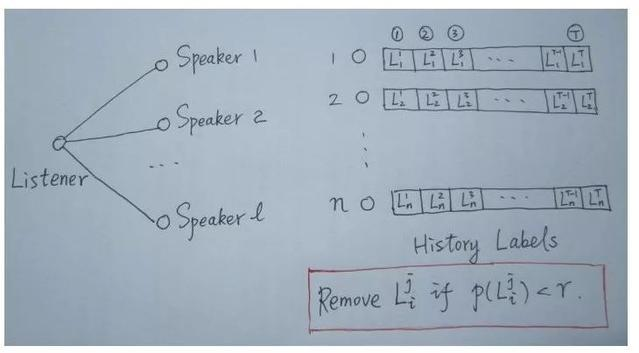
SLPA介绍了听众和演讲者的两个生动概念。可以以这种方式理解:在令人耳目一新的节点的过程中,我们说要刷新的节点被定义为听众,其接近节点是扬声器。有多个发言人。当许多说话者的七个嘴巴时,谁应该听?交点此时,我们必须制定规则。
在LPA中,我们做出具有最大风险的标签的决定。这实际上是一条规则。只是在SLPA框架中,规则的选择方法主要由用户指定(通常由业务逻辑和场景确定)。与LPA相比,SLPA的最大功能是,它不仅在刷新原始标签,而且还记录在刷新迭代过程中每个节点的历史标签序列(例如,迭代t。著名的手绘图纸)。当迭代停止时,将对每个节点历史标签序列中每个标签的频率进行统计爱游戏最新官网登录入口,并且根据给定的阈值滤除了看起来较小概率的标签。独立)。
反狂欢应用程序方案
1。消费者金融反欺诈
近年来,与传统的商业银行相比,消费金融业的快速发展已经形成了自己独特的优势:填写更少的领域,快速的在线运营,快速的审查速度和及时的贷款。由于缺乏信用信息,这些申请人通常会为消费金融公司带来巨大的信贷和欺诈风险(首先,但一些消费者金融公司没有查询信用报告的资格)。
如何在有限的信用记录中或“零”信用记录中执行更准确的风险控制和欺诈识别是消费者金融公司降低成本和提高效率的关键问题。通常有两个方案可以解决这个问题。一种是使用商业银行广泛使用的成熟评分卡模型;另一个是基于新兴的机器学习的信用预测(评分)模型。实际上,机器学习的使用巧妙地可以结合两种解决方案并相互补充。
机器学习的原材料是数据,数据主要分为三类:一个是用户提交的申请表信息; (信用报告公司,运营商,社会保障公积金中心,法院执行,医院等)。使用数据,第二步是进行功能工程,这也是整个算法中的核心步骤。第三步是运行模型。由于我们的主角是SNA,因此我们查看以下典型社区。
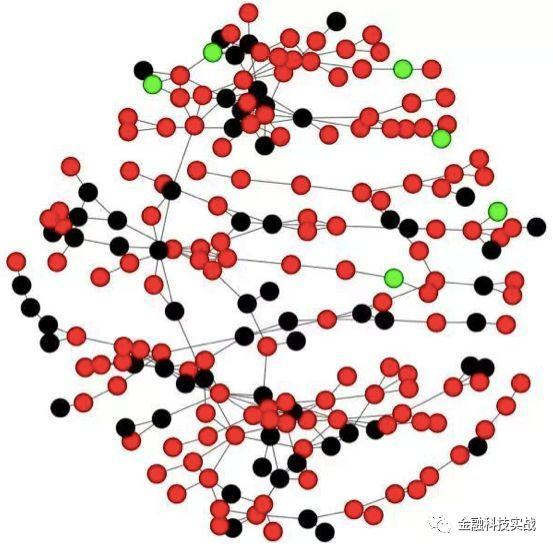
在图中,红点代表被拒绝的用户,黑点通过用户表示用户(通过应用程序应用但逾期的用户),绿点代表了表现良好的用户。总之,该团伙的拒绝率达到66.8%,表明该团伙的平均用户信用价值很低;该组的用户占所有用户的91.4%,进一步验证了该团伙的欺诈行为。
特别是,在使用SNA进行社区分析时,派系图的风险更高。这张照片的背后通常是一个多人团伙来犯罪。两个互连表示两个或两个理解。其背后的目的主要是彼此勾结,以满足消费者融资的要求。情况需要关注。
2。信用卡申请反欺诈
信用卡申请欺诈类似于消费者的财务,但是当前的平均信用卡水平仅为70%,有些银行甚至没有开始收集设备信息,因此他们缺乏一些在线电子信息。但是,由于信用卡中心具有查询用户信用数据的资格,因此与消费者融资相比,它将增加信用数据,并且是模型输入的一个很好的补充。
3。保险索赔反犯罪
SNA已被应用于保险索赔和反欺诈行为已有几年了。根据保险公司财产和保险风险控制部门的专家,自SNA算法发布以来,预先调查率每年可以提高2%。 ,为公司节省2亿+虚假赔偿。
识别汽车保险索赔欺诈案件通常使用涉及案件的车辆,包括驾驶员,记者,受益人和受伤者,以及维修店,报告电话,维护站点,GPS信息和其他数据等数据。例如,在2015年,Ping Insurance Lin Sheng的副总经理共享的案件:两辆上海车牌车辆和两辆江苏车牌车辆发生了碰撞事故。在互联网上,我发现这辆车的驾驶员是该案受伤的,一个案件的记者是另一个案件的驾驶员。通过进一步的调查和分析,发现两名驾驶员每年驾驶不同的车辆5次。
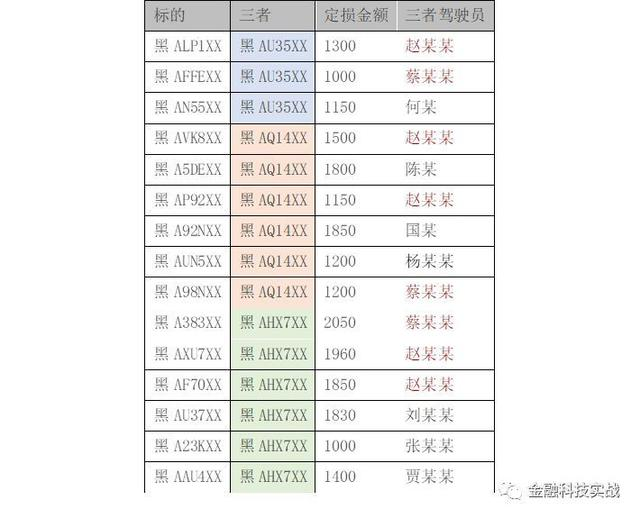
还有一个典型的情况可以与您共享。第一家维修工厂的员工驾驶道具,并充当三方故意造成事故的三人。在短期内,发出了高频危险。交通警察使用“微裁缝”的漏洞来射击车辆损失,而不是在现场调查并欺骗保险赔偿。通过SNA分析,除了维修店的Zhao Moumou和Cai Moumou外,还发现其他7名司机一口气赢得了这个欺诈帮派。
由于各种保险公司的价格一直是同质的,而且保险公司选择保险公司的基础不再是单独的价格敏感性,因此快速索赔已成为保险公司吸引保险公司的重要因素之一。因此,有少量的非法分子(
第四,销售网络反欺诈
销售网络反欺诈是方向的典型应用。为了促进销售,许多公司在促进产品和服务时制定了开发二级或较低级别代理商的委员会策略。通常,当下属代理商出售产品或服务时,上级代理商将从销售公司获得额外的奖励。例如,保险销售公司,如果二级代理商出售保险,那么上级代理商可以获得销售公司的1%佣金。这样,上级代理商使用该规则将其所有保险单悬挂在次要代理商上以获得非法收入。根据统计数据,在短短一年内,销售商店使用销售委员会奖励机制获得800万个额外的委员会(该案涉及的金额为8000万元)
PS:反欺诈是金融业的永恒主题,尤其是在大数据和人工智能时代。欺诈的风险已逐渐成为信贷风险之外的主要风险。为此,需要智能算法,例如社交网络分析,反欺诈将不断升级和优化手段。

