社交网络SNS的好友推荐算法
研究了数日有关社交平台推广的方法,发现当前众多应用程序都设有社交互动功能,这些功能与用户使用目的紧密相连爱游戏app官方网站登录入口,因此未来务必在此领域开发相应应用。早期的网络论坛主要提供信息交流服务,随后像优酷和土豆这类平台专注于视频内容传播,而网易云音乐则聚焦于音乐分享。相比之下,豆瓣网站内容较为丰富,涵盖了新闻资讯、音乐广播等多个方面。也尝试过一些用于社交的软件,比如脉脉、钉钉等。体验下来效果不理想,主要因为用户大多彼此陌生,互动也不频繁。这些平台普遍呈现两种情况,一是少数人拥有众多追随者,二是大量用户自身关注者寥寥且参与度低。究其原因,关键在于平台未能提供真正吸引人的内容。如同前日一般,腾讯视频忽然为我推荐了2007年播出的《远古入侵》,这个推荐十分精准!一部融合科幻、时空旅行、探险元素的外国剧集爱游戏最新官网登录入口,正适合这样标记的观众。
我们日常评估人际联系紧密程度时,会参考社交平台互动频次、媒介环境关联性、空间位置相似性等指标,这些因素都受个体活跃状态影响较大。此后研究者又从朋友的朋友、社群归属、共同爱好、讨论议题等维度展开探索。实际应用时我们同样会兼顾社交与兴趣两方面,寻求一个较为适宜的平衡点,向用户推荐其偏好的内容。
计算共同好友比例
通常推荐好友最便捷的方法是统计两人有多少共同熟人,倘若共同熟人数量众多,那么彼此相识的可能性就相当高。比如我和Jackie是校友,但我们或许都因为Facebook使用时间有限,可能并未互加好友,这时可以统计我和Jackie之间校友的比例有多大。其他诸如同事、亲属、朋友等关系也类似这种情况。利用社交平台, 能够依据既有的社交图谱为用户推荐潜在的朋友, 比如推荐用户朋友的朋友。这种基于朋友的朋友推荐方法, 可以用来为用户推荐在现实生活中彼此认识但在当前社交平台没有建立联系的其他人。比如使用校内网时, 经常发现一些许久未见的老同学出现在推荐好友的名单里。
好处在于精练、方便执行,成效显著。然而弊端同样突出,当个人社交圈成员不多时,无论是拓展新联系还是引荐他人都会遇到阻碍。此外,该技术仅考虑个体关联,未兼顾其他变量,可能导致推荐结果的精确度下降。
一种基础的朋友推荐方式是向用户推荐与其有最多共同相识者的人。这种方法的核心理念在于, 用户之间拥有越多的共同朋友, 表明他们之间建立联系的可能性越大。考虑到这种推荐机制容易受到个人社交网络规模的影响, 因此常常通过计算共同好友占各自好友总数的比例来衡量相似度, 并以此为基础进行朋友推荐。
在定向社交平台例如Twitter和新浪微博上, 用户u所关注对象out(u)与关注用户u成员in(u)是两个互不相同的群体, 故而通过共同熟人占比来衡量关联程度存在三种不同方式, 本研究选用辐射方向, 用户u和用户v的共有熟人比例fuv具体为:
其中, 用户u的粉丝列表是out(u), 用户v的粉丝列表是out(v) , out(u)和out(v)的交集为两者共同关注的用户, |out(u)|代表用户u的粉丝数量, |out(v)|代表用户v的粉丝数量
互动次数
不论彼此有多少熟人, 也不能保证关系会持续下去。平台总是鼓励用户多与人交流, 方便自身收集数据。一旦双方缺乏往来, 就算不上真正的朋友。
社交平台用户互动涵盖信息传递、意见交流、内容分享及资源保存等途径, 分享与评论等举动能够反映内容对个体的关注度, 而评论和分享这类动作往往被赋予不同的重要性, 为便于运算处理, 本研究中将信息传递、意见交流与内容分享这三类互动行为设定为同等价值。
用户u和用户v的互动情形iuv能够通过两者互动频次在用户u及用户v所有互动活动中的占比来体现, 本文所倡导的互动占比测算方式具体为:
其中, interact(u, v)代表个体u与个体v之间发生的互动频次, interact(u)则指个体u同所有其他个体发生的互动总量。两个个体间的互动频次以单向互动频次的算术平均值来衡量。
社交兴趣度
本研究对通过社交网络分析用户关联性的既有模式加以优化, 从彼此认识的人以及交流行为两个维度来衡量人际间的亲疏远近来,据此算出中心人物对潜在关联者的社交关注水平,借此说明中心人物与潜在关联者成为好友的可行性。
建立n个用户之间的关联数组A, A是一个n× n的表格, 其中, 若用户u和v存在好友关联(或用户u对用户v进行关注), 则数组中auv的值为1, 若不存在关联, 则auv的值为0。数组A中第u行ua= (au1, au2, , aun)表示了用户u的关联情况。

其中, fuv代表彼此相识的朋友数量占比, iuv代表彼此交流的活跃程度占比。α用于平衡这两方面因素, 取值因数据集而异, 可能需要通过经验预估或反复测试来优化。本研究将α设定为0.5。矩阵C中元素cuv反映了用户u与用户v关系的亲密程度。

在最近邻协同过滤方法里, 目标用户与最近邻在项目评分上高度接近, 所以目标用户未评分项目的预测值, 可以借助最近邻对该项目的评分进行加权平均来估算。同样地, 对于朋友之间的推荐, 可以把那些需要推荐的人当作需要评价的对象, 把朋友当作近邻, 把用户u和用户v之间关系的紧密程度, 理解为用户u给予用户v的打分, 或者是邻居用户v所具有的分量。


兴趣相似度
社交平台上的留言及活动能够揭示个人的关注点和期望。多数情况下,人们会借助日常用语或标记来表明自己的倾向,以此表达偏好。这种办法能够搜集到部分用户爱好的资讯, 不过其弊端相当显著, 自然语言解析能力难以准确把握用户表述, 同时个人喜好会不断演变, 爱好说明常会失去时效性, 此外多数情况下用户不清楚自身偏好, 或者难以用言语清晰表达喜好。所以, 要借助计算方法探寻个人过往活动记录, 用来判断其偏好, 再据此推送符合其爱好的内容。
衡量个体间偏好相近程度, 关键在于: 若彼此钟爱相同事物, 便表明志趣相投。微平台上的信息可视为载体, 倘若两位成员曾对某条动态进行过评论、传播或珍藏, 便昭示着他们情趣相近。不仅如此, 还能通过分析社交圈内成员的言论, 挖掘其兴趣标识(核心概念), 以此来评估个体间的志趣契合度。在标签式推荐里, 大部分情况下, 用户自行标注的标签数量非常有限, 这种现象或源于用户没有形成标记习惯, 或是用户刚刚注册, 或是用户参与度不高。所以, 一般会从用户发布的内容里筛选出关键词来充当标签, 或者利用标签间的关联性来扩充关键词。
本文借助既有认知来推算喜好关联程度。借助关键词向量来刻画喜好, 依托TF-IDF公式来衡量关键词分量, 依托关键词向量间的余弦距离来体现喜好关联程度。
通常情况下, 用户的关注点能够借助向量空间模型体现为一个关键词序列。从微博信息中获取关键词的步骤必须借助一些自然语言处理方法。关键词序列的形成过程涵盖了中文文本的切分、识别命名实体(例如人物姓名、地理区域、机构名称等)、关键词的排序以及关键词重要性的评估等。用户u的兴趣特征序列能够表现为

,N为用户总数, ni为包含ei的用户数目。
向量空间模型的长处在于它比较容易理解, 但它的短处是会舍弃部分内容, 例如词语彼此间的关联性。不过, 在大多数情况下, 该模型对于文本进行归类、分组、相似度评估时, 结果都相当令人满意。
用户间的喜好相近程度,能够借由喜好特征序列的余弦相似性来求取,具体方式如下:

余弦度量与相似程度相互对应,数值偏小意味着关联性弱,数值偏大则关联性强,数值介于零与一之间,零象征全然相异爱游戏app入口官网首页,一象征完全一致。
综合社交和兴趣的好友推荐
各种社交平台上的用户动机和关注点常有不同, 所以, 用户一般会在不同的社交站点构建各自的关系网。比如人人网上的好友多来自校友或熟人圈子, 豆瓣网上的好友则大多因共同爱好而结缘。为此本研究先测算交流意向系数和兴趣相近程度, 再将这两项指标整合评级, 最后筛选出评分最高的前k名用户进行推荐。只需核算有朋友关联的个体间的相仿朋友占比和互动程度, 便能够大幅提升效能。
社交网络结构固定不变, 不包含时间维度信息, 十年交情的老友和刚认识的人在网络图里表现相同;相比之下, 兴趣网络会随时间演变, 其变动通常体现在过往行为记录里。社交网络揭示的是人际交往习惯, 兴趣网络显示的是个人关注方向, 结合这两种网络分析, 推荐效果往往优于只分析单一网络的情况。为了更精准地调控这两个变量对最终成效的作用, 可以把社交关注度与兴趣相合度分别通过最大值进行标准化处理。最终体现社交联系和喜好倾向的综合评价可以用以下公式表示
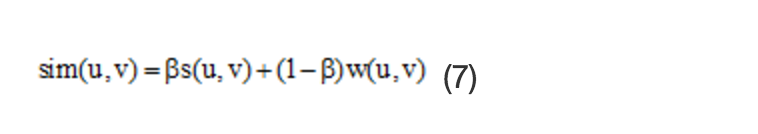
其中, β 是优化推荐方法的一个可调变量, 代表最终评分里社交层面的重要性, β 的数值在某个区间内, 在本次研究中β 设定为0.5。s(u, v)用来衡量社交层面的契合度。w(u, v)用来衡量兴趣层面的相似程度。
本文好友推荐算法执行过程如图1所示:
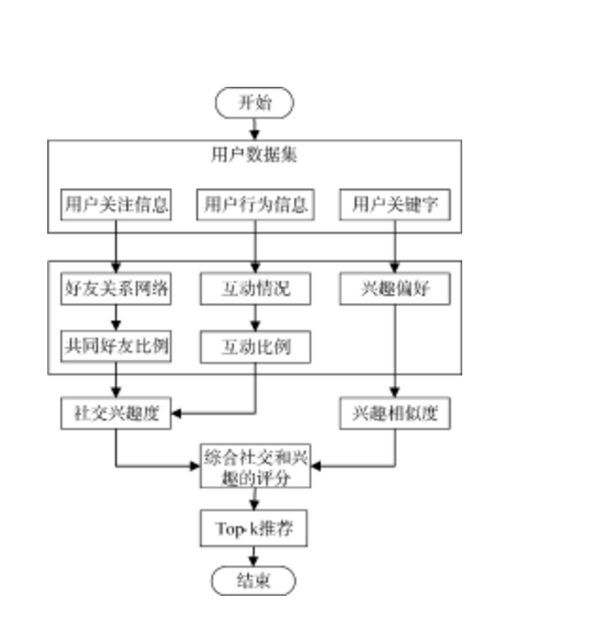
图1 基于社交和兴趣的好友推荐方法 实验与分析
根据 2012 年 KDD 大赛的腾讯微博数据, 选出部分数据作为本次研究的实验素材, 并运用所设计的算法进行测试评估。收集到的信息涵盖用户之间的关注互动, 用户的社交活动, 如接收通知、分享内容和发表评论等, 还包含用户关注的关键词及其对应的权重值。
从社交平台中随机挑选五个互动频繁的用户作为初始点, 运用广度优先方法搜集用户之间的连接关系, 排除拥有朋友数量少于五个或者超过一百五十个的用户, 这样最终筛选出三千二百三十七个用户, 用来构建一个微型社交网络模型。在后续的测试环节, 仅分析这些用户之间的朋友关联情况。每个用户平均关注13.4位其他人, 这种联系模式相当松散, 网络的松散程度高达99.6%, 数据呈现出极为突出的长尾分布特征。借助先前获取的用户名单, 分别从个人的社交活动和使用的关键词中, 提取出相关的社交互动记录和关键词信息。实验数据的处理流程参见图1。通过分析关联图谱得出彼此熟识度数值, 依据活动记录得出互动程度数值, 将彼此熟识度数值与互动程度数值整合得出社交亲密度。接着依据个人标签生成意向矩阵, 由此得出意向匹配度。最终融合社交亲密度与意向匹配度得出综合等级, 将综合等级最高的前k位成员推送给指定对象。
在排序模型中,经常采用精确度、召回力以及F1值作为衡量标准,这些指标的具体含义如下:

实验对比了四种好友推荐方法的表现,分别是依据熟人数量,依据爱好相近程度,依据熟人数量和爱好相近程度,以及依据社交关系和爱好相近程度。





